Our AI Beats Claude: Your Reddit Q's Answered
Our self-evolving modular AI made waves on Reddit when it beat Claude on a long, complex task. We recap user comments and address the most frequently asked questions.
In case you missed it, a recent post about our self-evolving architecture on r/agi drove a little Reddit bump of interest in what we're building. What grabbed people's attention was this demo showing our AI self-evolving to get really good at Tower of Hanoi, excelling at something that Claude 3.7 fails miserably at.
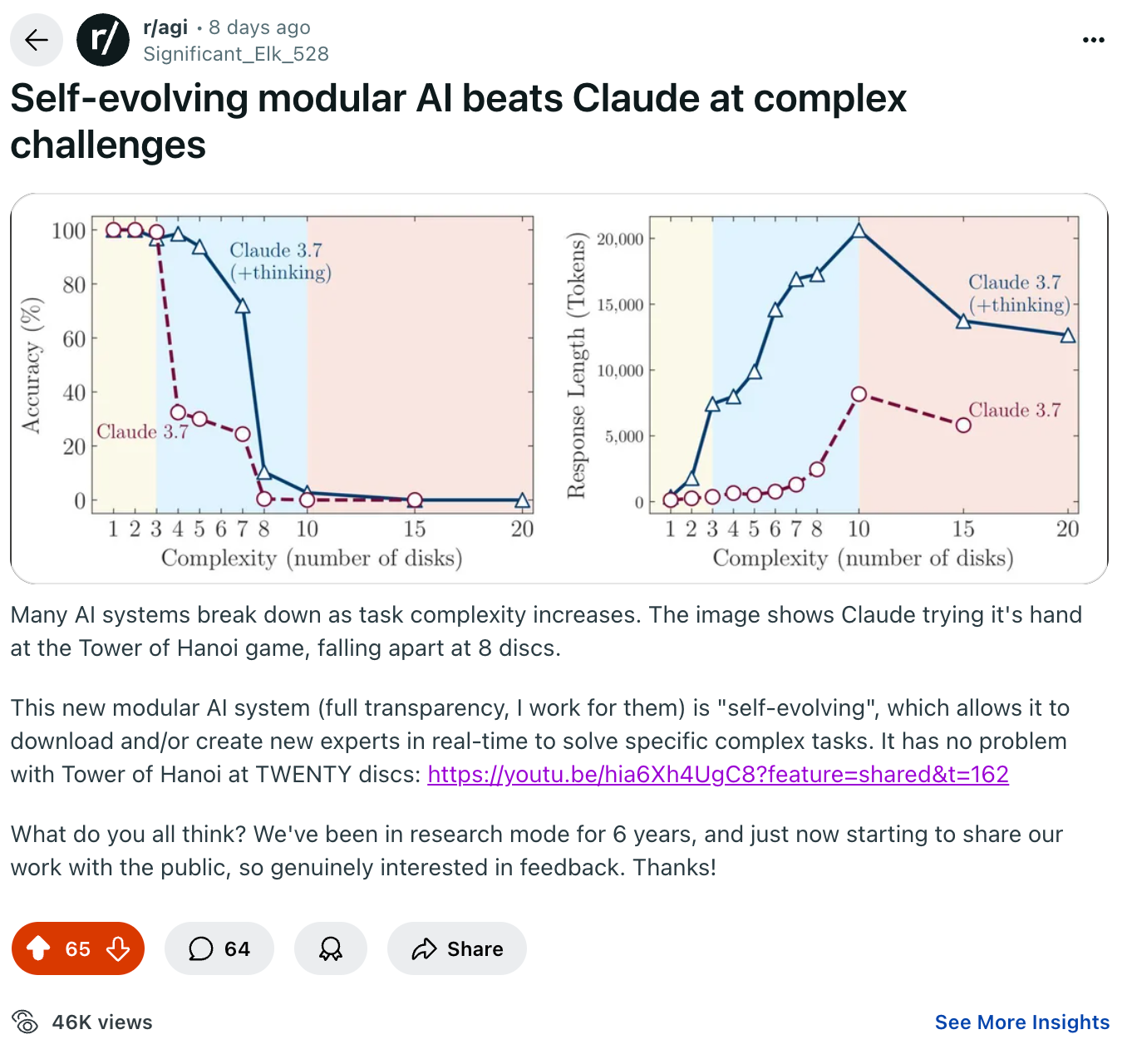
The excitement reinforced our belief that we're building something truly unique, and it goes to show that there is real interest among AI early adopters for something beyond LLM-based chatbots. The community is keen to experience human-level artificial intelligence, which we're set on unlocking with our self-evolving architecture.
We want to make some space here on our blog to recap the primary themes of the convo in the Reddit comments, and provide clarity, insights, and answers accordingly. So let's dive in!
How It Works
A lot of people just wanted a clearer understanding of exactly how our technology works. While we can't divulge every detail, we've provided an overview on the Our Tech page of our site, and more detail can be found across our blog entries, especially under the Tech Deep-Dives tag.
Third-Party Benchmark Validation
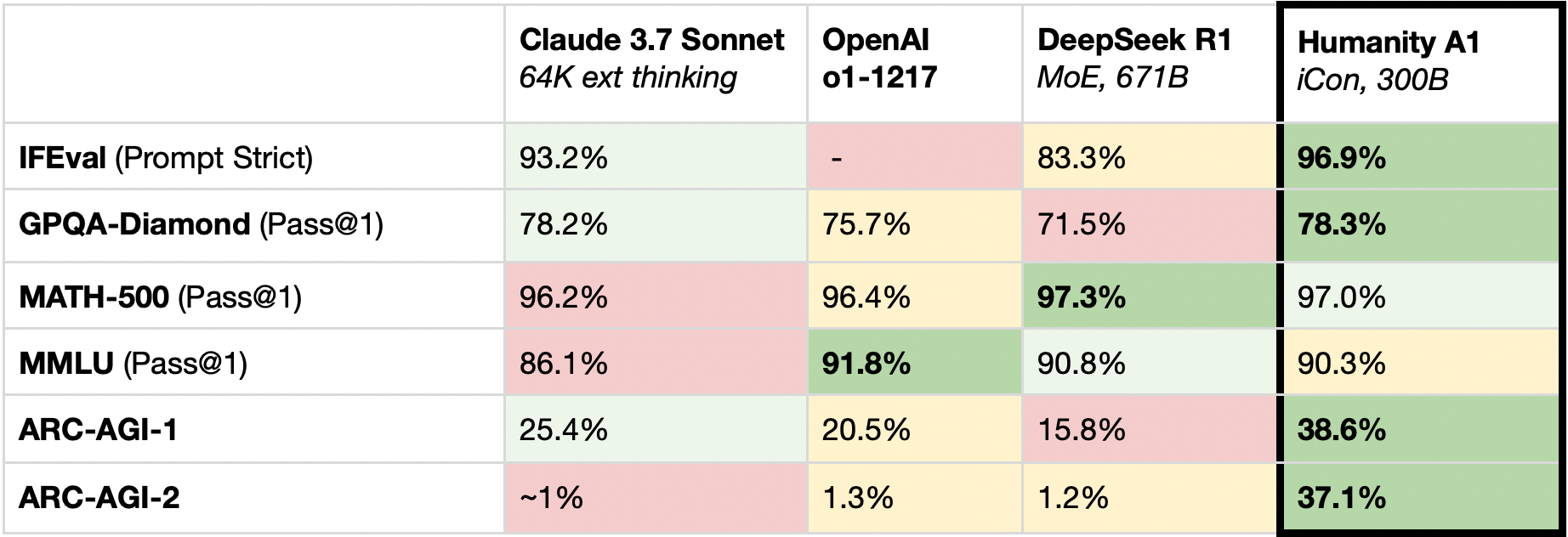
We have received reasonable skepticism regarding our published benchmark scores. This is because a) Our scores are truly impressive 😎, and; b) our scores haven't been validated by a third-party—they aren't published on benchmark leaderboards accordingly.
There are logistical reasons why we haven't been able to obtain official listing on benchmark leaderboards, but we have two updates regarding this:
- We are working to get externally verified benchmark results as soon as possible — stay tuned!
- In the meantime, we are open right now to providing API access to qualified parties who would like to verify our benchmark scores: Contact us here >
Hallucination Mitigation Evidence
One important feature of our AI architecture is increased accuracy and reduced hallucinations. Some Redditors see this claim as specious without definitive evidence. As of right now, we're pointing to our benchmark results and accepted academic experimental results (via IMOL (Intrinsically Motivated Open-Ended Learning) 2025, we'll share more on that soon) as evidence that our structure of niche Domain Experts + Verification Experts, combined with extrinsic and intrinsic self-learning, does indeed lead to very high accuracy and lower hallucination rates that today's frontier models (e.g., OpenAI's ChatGPT-5, Anthropic's Claude 3.7).
However, we understand the questions regarding this capability. We believe that as we start to release demos and beta tools/products, people will be able to see this feature in action for themselves. In the meantime, we will be performing ongoing research on the hallucination-mitigation aspects of our system and will publish our findings accordingly. As that research progresses, we hope to submit our findings for academic peer review.
Safety Considerations
Along with optimism about our work came some good questions about how we're thinking about safety. A proper self-evolving AI may manifest emergent behavior or capabilities that make safety a top priority.
We are currently working on developing and testing a Code of Conduct for our self-evolving AI system, along with a safety policy, both of which we will share here on our website for transparency. Until these two steps are complete, we will not be making our self-evolving AI available to users outside of our company (this should be distinguished from assemblies of our modular AI system that do not engage in autonomous self-learning). Additionally, for the time being, our self-evolving AI is run on local machines (rather than distributed compute), giving us the ability to fully shut down the system should the need arise.
Partner with Us
We currently have a variety of collaboration opportunities, from our Advisory Board and research positions to design partnerships and more.
If you just want to stay in the loop as our work progresses, sign up for our email newsletter for twice-monthly updates.
humanity.ai Newsletter
Join the newsletter to receive the latest updates in your inbox.

